
Стратегия внедрения DeepSeek V4: как оптимизировать и масштабировать бизнес с помощью ИИ

Сегодня углубимся в возможности DeepSeek V4 — модели, которая может перевернуть представление о соотношении цены и качества в ИИ‑технологиях.
Разберём детально, почему она стоит внимания, как применять на практике и минимизировать риски. 👇
🔮 Что такое DeepSeek V4?
На апрель 2026 года DeepSeek V4 закрепилась как новый индустриальный стандарт в Open Source‑моделях. ✨
Почему она уникальна:
✅ Использует инновационную архитектуру Mixture‑of‑Experts (MoE), которая позволяет модели «специализироваться» в разных областях.
✅ Обучена на колоссальных 33 трлн токенов — это ставит её в один ряд с самыми продвинутыми закрытыми решениями.
✅ Полностью доступна в России без VPN и зарубежных SIM‑карт — критически важно для бесперебойной работы бизнеса 🇷🇺.
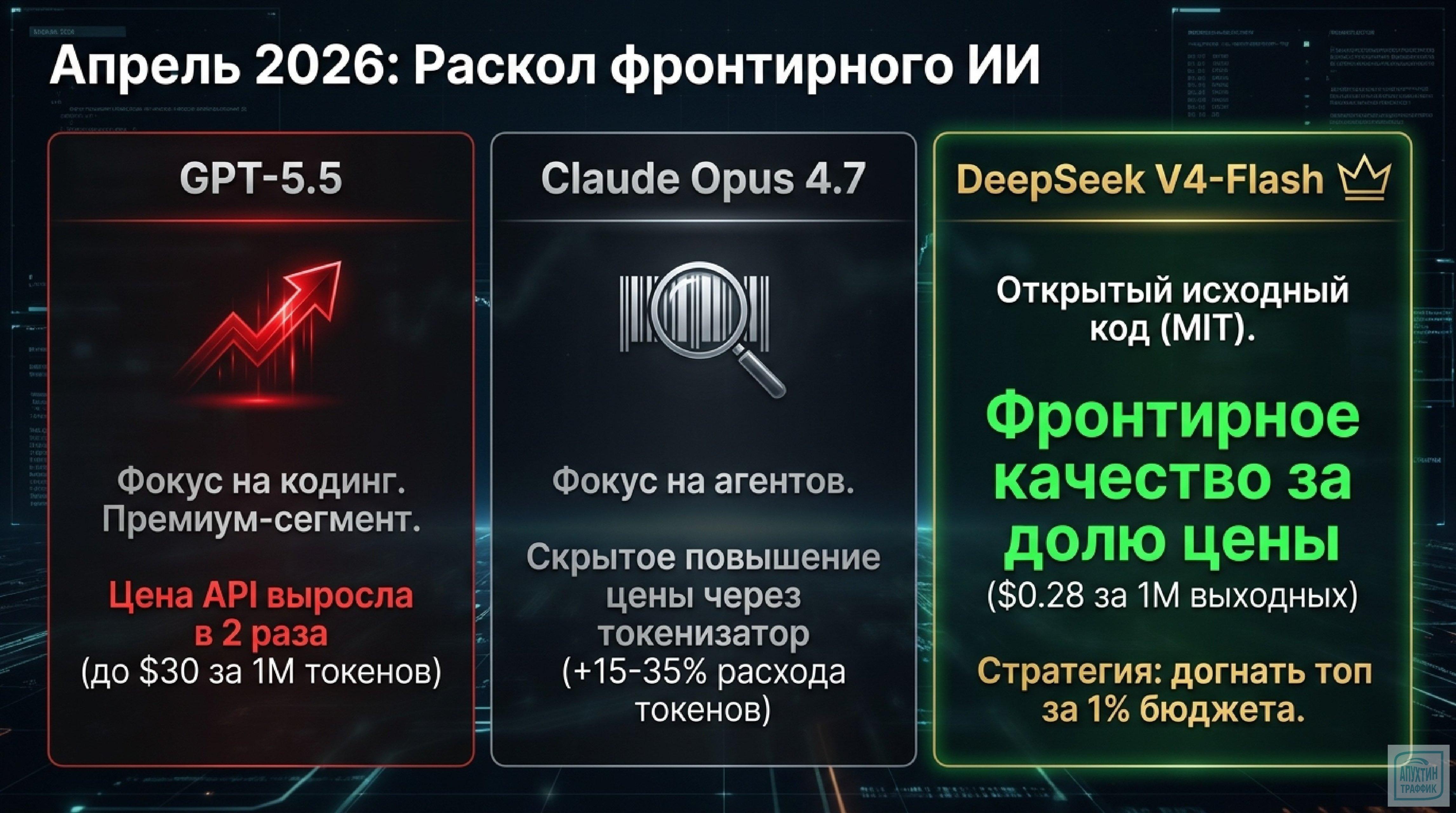
Ключевые версии:
🟦 DeepSeek‑V4‑Pro (1,6 трлн общих параметров, 49 млрд активных) — флагман для сложных когнитивных задач (например, стратегическое планирование, анализ больших данных).
🟩 DeepSeek‑V4‑Flash (284 млрд параметров, 13 млрд активных) — оптимизирована для массовых операций (чат‑боты, модерация контента) с высокой скоростью.
Технологический фундамент:
Muon — оптимизатор, обеспечивающий быструю сходимость и стабильность обучения.
mHC (Manifold‑Constrained Hyper‑Connections) — технология, повышающая «выразительность» модели и стабильность сигнала в глубоких сетях.

⚡ Технические преимущества: революция в масштабировании
Концепция Inference‑Time Scaling (масштабирование во время инференса) — главный прорыв. Модель динамически распределяет ресурсы, «размышляя» над сложными задачами, что кратно повышает точность. 💡
Как это работает на практике?
Революция бесконечного контекста (1 млн токенов)
Гибридная архитектура внимания с двумя технологиями:CSA (Compressed Sparse Attention):
Сжатие 1:4 сохраняет структуру данных, позволяя обрабатывать длинные тексты без потери смысла.
Пример: анализ юридических документов объёмом в сотни страниц — модель «видит» связи между абзацами, которые человек упустит.HCA (Heavily Compressed Attention):
Экстремальное сжатие 1:128 для обработки гигантских массивов данных (например, IT‑проекты с тысячами файлов кода).
Пример: аудит безопасности системы — модель анализирует весь кодовый ландшафт, выявляя уязвимости, которые разбросаны по разным модулям.
Эффективность инференса
Комбинация CSA/HCA и квантования FP4 даёт:Версия Pro требует в 10 раз меньше KV‑кэша (всего 10% от DeepSeek‑V3.2).
Потребление вычислительных мощностей (FLOPs) — 27% от предшественников при работе с длинным контекстом.
Итог: экономия ресурсов без потери качества.
Бенчмарки фронтирного уровня
В режиме Pro‑Max модель превосходит Gemini 3.1 и GPT‑5.4:SimpleQA Verified — 57.9% (ответы на простые вопросы с верификацией фактов).
SWE Verified — 80.6% (автоматическое исправление ошибок в коде).
Вывод: DeepSeek V4 — лидер в решении задач, требующих «агентских» способностей (автономное выполнение сложных действий).

Коротко:
DeepSeek V4 умеет «думать глубже» и обрабатывать больше данных, чем конкуренты, при этом экономя ресурсы. Это делает её идеальной для задач, где важны и точность, и масштабируемость.
💰 Экономический анализ: DeepSeek V4 vs GPT‑5.5
Почему переход на DeepSeek V4 неизбежен с точки зрения бизнеса? Давайте посчитаем! 📊
Сравнение стоимости API за 1 млн токенов (USD):
GPT‑5.5:
Ввод (Cache Miss): $5.00
Вывод: $30.00
DeepSeek‑V4‑Pro (со скидкой 75% до 31 мая 2026, 15:59 UTC):
Ввод: $0.435
Вывод: $0.87
Экономия: в 57 раз на вводе и в 34 раза на выводе!
DeepSeek‑V4‑Flash:
Ввод: $0.14
Вывод: $0.28
Экономия: в 35 раз на вводе и в 107 раз на выводе.

Примеры экономии для бизнеса
Чат‑боты поддержки (массовый сервис):
Используйте Flash для обработки 10 млн токенов в месяц:GPT‑5.5: 10 000 000 × ($0.14 + $0.28) = $4 200.
DeepSeek‑V4‑Flash: 10 000 000 × ($0.14 + $0.28) = $420 (в 10 раз дешевле).
Юридический аудит (сложные задачи):
Используйте Pro для 1 млн токенов:GPT‑5.5: $5.00 (ввод) + $30.00 (вывод) = $35.
DeepSeek‑V4‑Pro: $0.435 (ввод) + $0.87 (вывод) = $1.305 (в 26.8 раз дешевле).
Генерация контента для e‑commerce (средний бизнес):
1 млн токенов в месяц:GPT‑5.5: $35 (примерная стоимость).
DeepSeek‑V4‑Flash: $0.42 (в 83 раза дешевле).

Ключевой момент:
Скидка 75% на Pro действует до конца мая — это окно для миграции с минимальными затратами. После 31 мая стоимость может вырасти, поэтому откладывать невыгодно.
Вердикт:
DeepSeek V4 позволяет масштабировать ИИ‑процессы без взрывного роста расходов. Это особенно важно для:
стартапов, ограниченных в бюджете;
крупных компаний, работающих с большими объёмами данных;
B2B‑сервисов, где стоимость API напрямую влияет на маржинальность.

🛠️ Практические бизнес‑кейсы: где применять и как решать проблемы
Разберём кейсы с примерами, типичными ошибками и способами их устранения.
Repository‑level Engineering (AI‑архитектор) 🧱
Суть:
Модель анализирует зависимости между тысячами файлов, видя весь IT‑ландшафт проекта. Используется для:рефакторинга кода;
аудита безопасности;
предсказания багов на уровне архитектуры.
Пример:
Компания разрабатывает облачный сервис. DeepSeek‑V4‑Pro анализирует 1 млн строк кода, выявляя:повторяющиеся фрагменты (оптимизация);
уязвимости в интеграциях с API;
потенциальные конфликты между модулями.
Типичные ошибки:
Перегрузка модели. Если передать слишком много данных разом, модель «теряет фокус».
Решение: сегментировать проект на модули, обрабатывать их последовательно, сохраняя контекст через CSA.Некорректные выводы. Модель может пропустить редкие баги.
Решение: внедрить Human‑in‑the‑loop — финальную проверку результатов инженером.Проблемы с конфиденциальностью. Исходный код может содержать чувствительные данные.
Решение: анонимизировать данные перед обработкой или использовать локальные серверы (On‑premise).
HR и интеллектуальный найм 👥
Возможности:
автоматизация составления планов интервью;
генерация тестовых заданий для проверки компетенций;
скрининг резюме с выделением ключевых навыков.
Пример:
Рекрутинг DevOps‑инженеров. Модель:создаёт чек‑лист вопросов по Kubernetes, Docker, CI/CD;
генерирует задание на настройку кластера;
анализирует резюме, выделяя опыт работы с облачными технологиями.

Типичные ошибки:
Смещение в тестовых заданиях. Модель может генерировать нерелевантные или слишком сложные задачи.
Решение: калибровать модель на отраслевых данных, проверять задания у экспертов.Предвзятость в оценке резюме. Модель может дискриминировать кандидатов по полу, возрасту.
Решение: использовать деанонимизированные данные для обучения, внедрить аудит результатов.Ложные срабатывания. Модель может неверно интерпретировать ключевые слова.
Решение: добавить этап ручной проверки топ‑кандидатов.
Глубокий анализ клиентского опыта 📊
Применение:
Массовая загрузка отзывов с маркетплейсов (Wildberries, Ozon) для выявления:скрытых дефектов продукта;
предпочтений аудитории;
трендов, которые упускают конкуренты.
Пример:
Производитель смартфонов анализирует 100 тыс. отзывов. Модель выявляет:частые жалобы на быстрый разряд батареи;
положительные отзывы о камере в низком освещении;
запрос на добавление функции разблокировки по лицу.
Типичные ошибки:
Искажение данных. Отзывы могут содержать сарказм, опечатки, сленг.
Решение: обучить модель на размеченных данных с учётом нюансов языка.Пропуск редких, но важных проблем. Модель фокусируется на популярных темах.
Решение: настроить веса для редко встречающихся, но критичных фраз (например, «сломалось через неделю»).Контекстуальные ошибки. Отзыв может касаться старой версии продукта.
Решение: фильтровать данные по дате, версии товара.
Агенты с «бесконечной памятью» 🧠
Принцип:
Благодаря CSA, агенты сохраняют контекст взаимодействий на месяцы, не теряя брендового голоса.Примеры:
Чат‑бот поддержки, который помнит предыдущие обращения клиента (даже через полгода).
Виртуальный ассистент, который адаптирует стиль общения под предпочтения пользователя.
Корпоративный помощник, хранящий историю встреч и поручений.
Типичные ошибки:
Накопление «шума». Со временем агент может «запутаться» в избыточных деталях.
Решение: периодически «сбрасывать» неактуальный контекст, сохраняя ключевые моменты.Утечка данных. История диалогов может содержать конфиденциальную информацию.
Решение: шифровать контекст, ограничить доступ к данным через API.Несоответствие тону бренда. Модель может случайно изменить стиль общения.
Решение: регулярно калибровать модель на примерах идеальных диалогов.
Дополнительные кейсы
Финансовый сектор: анализ транзакций в масштабе 1 млн записей для выявления мошенничества.
Маркетинг: генерация персонализированных email‑рассылок на основе истории покупок клиента.
Медицина: обработка медицинских карт для выявления скрытых корреляций между симптомами и заболеваниями.

🗺️ Дорожная карта гибридного внедрения (ROI Roadmap)
Трёхфазный подход для минимизации рисков и максимизации возврата инвестиций.
Фаза 1: Операционная эффективность (Short‑term)
Цель: быстро сократить затраты на текущие API, не меняя бизнес‑процессы.
Шаги:
Выберите рутинные задачи для пилотного проекта:
поддержка клиентов (чат‑боты);
модерация контента;
суммаризация встреч;
обработка FAQ.
Замените текущие модели на DeepSeek‑V4‑Flash.
Почему Flash? Высокая скорость и низкая стоимость идеальны для массовых операций.Настройте интеграцию через API, уделяя внимание:
лимитам токенов;
формату входных/выходных данных;
мониторингу ошибок (429 Too Many Requests, 500 Internal Server Error).
Зафиксируйте метрики:
время ответа модели;
удовлетворённость клиентов (NPS, CSAT);
экономия бюджета.
Масштабируйте успешные сценарии на весь отдел.
Ожидаемый результат:
Снижение затрат на API в 10–30 раз в течение 1–3 месяце.
Риски и решения:
Перегрузка API. Ограничьте количество параллельных запросов, используйте кэширование ответов.
Проблемы совместимости. Протестируйте интеграцию на малом объёме данных, документируйте API‑вызовы.
Снижение качества. Сравните ответы Flash с Pro на тестовых задачах — если критично, используйте Pro для части задач.

Фаза 2: Глубокая интеграция и разработка (Mid‑term)
Цель: внедрить модель в сложные процессы, повысить качество решений.
Шаги:
Определите ключевые области для глубокой интеграции:
R&D (генерация кода, проектирование алгоритмов);
юридический аудит (анализ договоров, выявление рисков);
сложная разработка (автоматизация тестирования, проектирование API).
Используйте DeepSeek‑V4‑Pro для задач, требующих высокой когнитивной нагрузки.
Активируйте Thinking Mode для принятия стратегических решений:
моделирование бизнес‑сценариев;
прогнозирование спроса;
оптимизация цепочек поставок.
Обеспечьте Bitwise Reproducibility (битовую воспроизводимость):
используйте детерминированные ядра DeepSeek;
зафиксируйте версии библиотек и параметры обучения;
тестируйте стабильность в корпоративных системах.
Создайте гибридные системы:
объедините DeepSeek с внутренними базами данных (через RAG);
добавьте экспертный контроль (Human‑in‑the‑loop) для критически важных задач.
Настройте мониторинг ключевых метрик:
точность ответов;
время принятия решений;
ROI от внедрения.
Ожидаемый результат:
Сокращение времени на R&D, снижение юридических рисков, повышение качества продуктов — в среднем через 3–6 месяцев.
Риски и решения:
Высокая нагрузка на инфраструктуру. Используйте облачные ресурсы с возможностью масштабирования (например, GPU‑кластеры).
Ошибки в сложных задачах. Внедряйте модель поэтапно, начиная с наименее критичных сценариев.
Зависимость от API. Рассмотрите частичный переход на On‑premise.
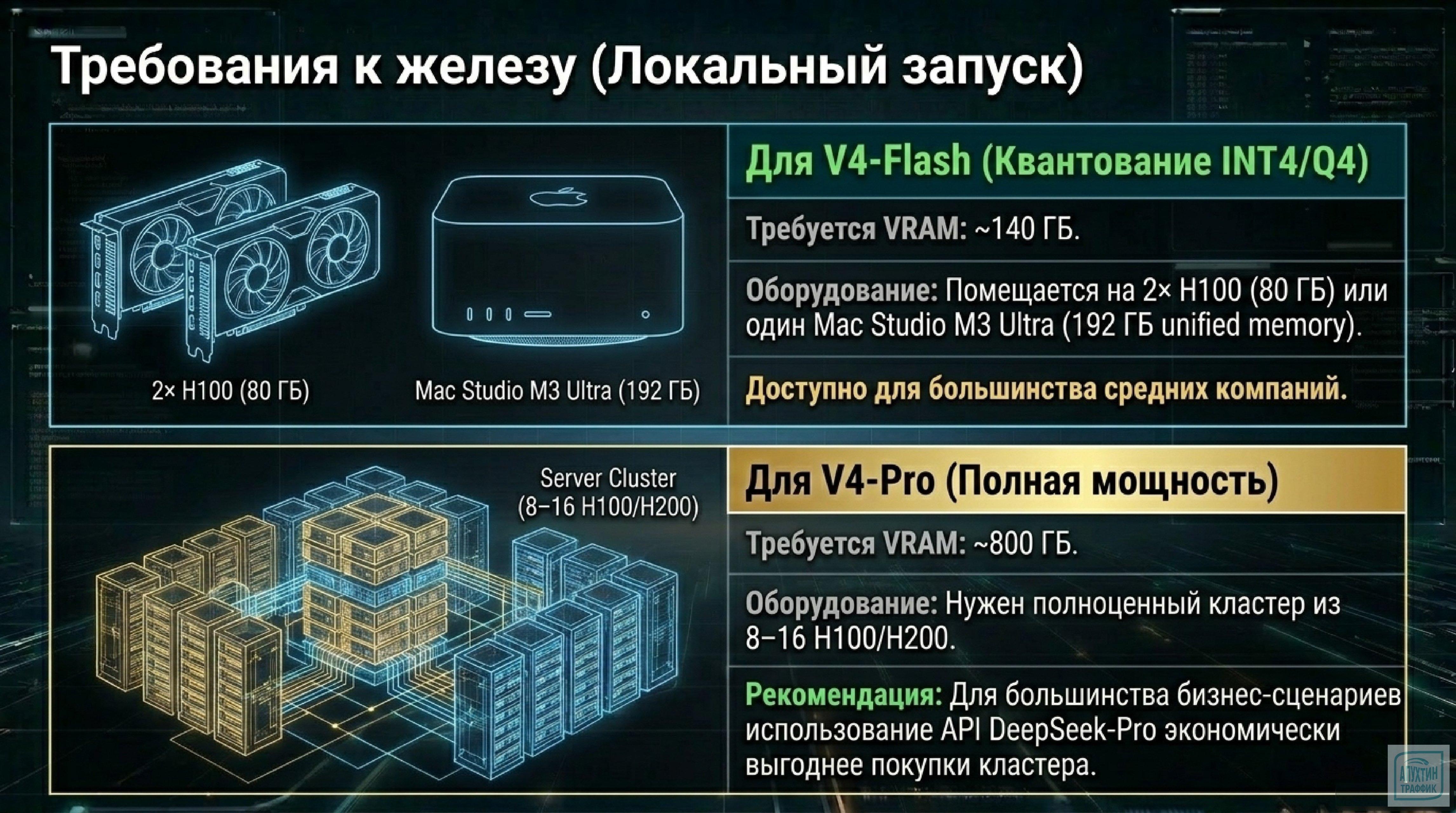
Фаза 3: Локальное развёртывание и безопасность (Long‑term)
Цель: полный контроль над данными, максимальная безопасность, независимость от внешних провайдеров.
Шаги:
Перенесите модель на собственные серверы (On‑premise):
оцените требования к железу (GPU, RAM, дисковое пространство);
выберите платформу (Docker, Kubernetes);
обеспечьте соответствие GDPR, ФЗ‑152 и другим нормативам.
Используйте Pro‑Max для критичных узлов бизнеса:
стратегическое планирование;
управление рисками;
разработка прорывных продуктов.
Создайте локальные бэкапы весов модели — защититесь от изменений лицензионной политики.
Настройте прокси‑слои для маскировки чувствительных данных:
анонимизируйте PII (персональные данные);
шифруйте конфиденциальную информацию;
ограничьте доступ через IAM‑системы.
Регулярно обновляйте модель, используя открытые веса и новые версии.
Ожидаемый результат:
Полная независимость, снижение рисков утечек, возможность кастомизации модели под уникальные задачи — через 6–12 месяцев.
Риски и решения:
Высокие затраты на инфраструктуру. Рассчитайте TCO (Total Cost of Ownership) — часто долгосрочная экономия перевешивает.
Сложности с развёртыванием. Привлекайте DevOps‑команды, используйте готовые фреймворки (например, TensorFlow Serving).
Устаревшие модели. Следите за обновлениями DeepSeek, регулярно переобучайте модель на внутренних данных.

⚠️ Риски и безопасность: что нужно учитывать
Геополитическая зависимость
Использование китайских опенсорс‑решений может повлечь изменения лицензионной политики.
Митигация:
✅ регулярно создавайте локальные бэкапы весов модели;
✅ продублируйте критически важные данные в нескольких регионах;
✅ следите за новостями в сфере регулирования ИИ.Локальные регуляторные «галлюцинации»
Модель может ошибаться в специфике регионального законодательства (например, налогообложение самозанятых).
Митигация:
✅ используйте RAG с актуальной базой законов (обновляйте ежемесячно);
✅ внедрите Human‑in‑the‑loop — экспертная проверка результатов перед публикацией;
✅ тестируйте модель на кейсах из судебной практики.Конфиденциальность данных
При работе через API есть риск утечки чувствительных данных.
Митигация:
✅ настройте прокси‑слои с анонимизацией (маска имён, адресов, номеров счетов);
✅ используйте шифрование (TLS 1.2+);
✅ ограничьте доступ к API через IP‑whitelisting.Этические риски
Модель может генерировать предвзятый или оскорбительный контент.
Митигация:
✅ обучите модель на сбалансированных данных;
✅ внедрите фильтры для блокировки запрещённой лексики;
✅ проводите аудит результатов с привлечением этического комитета.

✅ Итоговые рекомендации
DeepSeek V4 — это не просто модель, а инструмент для трансформации бизнеса. Почему это важно:
Цена. Фронтирный интеллект по цене массового продукта — экономия до 99% на API.
Масштабируемость. Обрабатывает 1 млн токенов, что позволяет анализировать целые проекты, базы данных, библиотеки кода.
Локальная доступность. Работает без VPN в России — критично для соблюдения сроков и непрерывности процессов.
Гибкость. Две версии (Pro и Flash) подходят для разных сценариев — от рутинных задач до сложных R&D.
Кому особенно стоит присмотреться:
Стартапам: экономия бюджета позволяет быстрее выйти на рынок.
Средним компаниям: масштабирование ИИ‑процессов без роста затрат.
Крупным корпорациям: снижение TCO (общей стоимости владения) ИИ‑инфраструктуры.
Отрасли с большими данными: финтех, e‑commerce, медицина, юриспруденция.
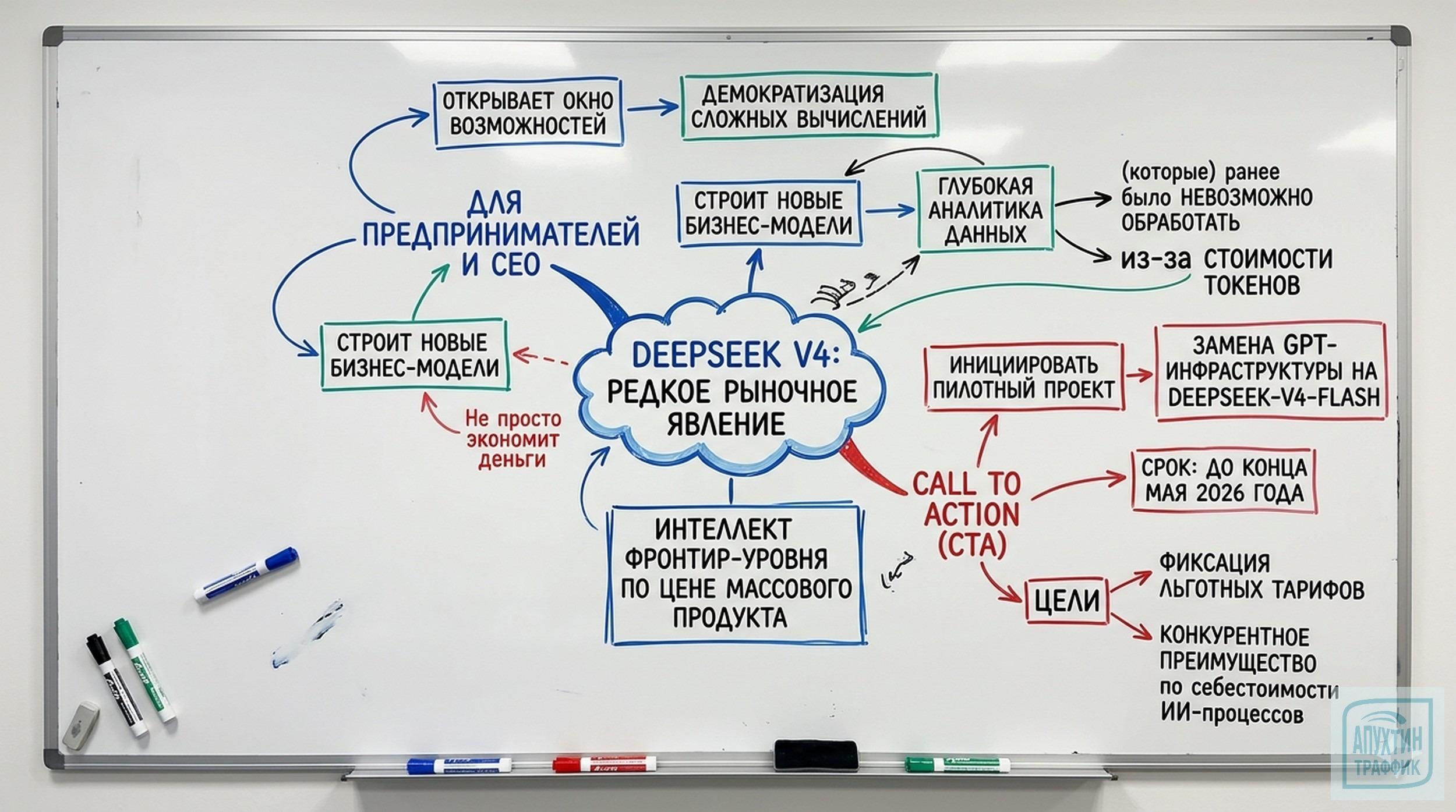
Конкретные шаги для внедрения:
До конца мая 2026:
Запустите пилотный проект на DeepSeek‑V4‑Flash, чтобы зафиксировать льготные тарифы. Начните с 1–2 рутинных задач (например, модерация комментариев).Через 1–3 месяца:
Анализируйте метрики. Если экономия очевидна, расширяйте применение на другие отделы.Параллельно:
Начните подготовку к глубокой интеграции (фаза 2): соберите внутренние данные, определите сценарии для Pro.В долгосрочной перспективе:
Рассмотрите локальное развёртывание (On‑premise), чтобы полностью контролировать данные и избежать зависимости от API.